Travail sur les textes en Python ¶
Nous allons découvrir comment avec quelques routines Python, nous pouvons explorer le contenu de certains fichiers numériques.
Il faut pour cela que leur contenu soit dans un format ouvert: c'est le cas de tous les fichiers du web, notamment ceux développés par le W3C comme le fichier image au formet PNG.
En revanche on ne pourra pas lire les fichiers générés par des logiciels propriétaires comme Microsoft ou Apple... ces fichiers étant cryptés.
Ouverture d'un fichier.¶
Préparation
- Construire un dossier
TP_traitement_textedans lequel vous enregistrerez tous vos fichiers. - Télécharger ici le fichier sur lequel nous allons tester nos codes python.
Il s'agit d'un fichier texte contenant la constitution française. Nous allons analyser ce fichier texte.
Comment lire et écrire sur des fichiers en Python?
Pour ouvrir le fichier en mode lecture, nous allons utiliser les routines suivantes:
fich = open("test.txt", 'r', encoding = "utf-8") # r comme read
fich est un objet tampon contenant tous les caractères du fichier texte mais ce n'est pas une chaîne de caractères: il faut lire cet objet et stocker l'information dans une variable.
fich = open("test.txt", 'r', encoding = "utf-8") # r comme read
contenu = fich.read() #lit tout le texte et l'affecte à la la variable contenu
Info
La variable contenu est alors une chaîne de caractères.
Évitez de printer la valeur de contenu dans la console qui est extrêmement grande!
Taille du texte
Faites afficher dans la console la taille de la variable contenu et comparez-la à la taille du fichier texte que vous avez ouvert.
La méthode read permet de lire tout le contenu de l'objet fich.
On peut aussi lire ligne par ligne le fichier:
fich = open("test.txt", 'r', encoding = "utf-8") # r comme read
cpt = 1
contenu = fich.readline() #lit la première ligne
while contenu != "":
contenu = fich.readline()
cpt += 1
print(cpt)
contenu prend à chaque tour de boucle, la valeur de chaque ligne du fichier. La variable cpt compte ici le nombre de ligne dans le fichier.
On peut aussi:
- ouvrir un fichier en écriture mais attention: si ce fichier existe déjà son contenu sera alors détruit
- ouvrir un fichier en ajout pour ajouter à un fichier existant de nouvelles informations.
fich = open("mon_texte.txt", 'w') # ouverture en écriture
fich.write("bonjour!") #écris dans le fichier txt
mon_texte.txt n'existe pas, il est alors créer: s'il existe son contenu est effacé.
fich = open("mon_texte.txt", 'a') # ouverture en écriture en mode append
fich.write("bonjour!") #écris dans le fichier txt
mon_texte.txt n'existe pas, il est alors créer: s'il existe son contenu est préservé.
Il existe aussi le mode rb pour une lecture binaire(plutôt hexadécimale...) du fichier, mode que nous n'utiliserons pas ici.
Fermer le fichier ouvert
À chaque fois que vous ouvrirez un fichier pour le lire, le modifier ou le créer, il faudra toujours penser à le fermer à la fin du programme par l'instruction fich.close()
Nous allons d'abord travailler sur le fichier test.txt afin de le simplier:
- on va remplacer toutes les majuscules par des minuscules
- on va remplacer les caractères accentués les plus usités par le caractère correspondant sans accent (
é,è,ùetà).
Prération du fichier
- Ouvrez le fichier
test.txten lecture puis stockez son contenu dans une variabletexte_originalde typestring. - Construire un programme Python qui à partir d'une chaîne de caractères, construit une nouvelle chaîne de caractères en remplaçant toutes les majuscules par des minuscules(voir le cours sur les chaînes de caractères...)
- Construire un programme Python qui à partir d'une chaîne de caractères, construit une nouvelle chaîne de caractères en remplaçant les caractères accentués usuels par leur correspondant sans accent.
- Appliquez les deux programmes précédents à l'objet
texte_originalpour obtenir la chaînetexte_filtre. - Ouvrez un fichier
fichier_test_filtre.txten écriture et y écrire le contenu de la variabletexte_filtre. - N'oubliez pas de fermer les fichiers ouverts!
Transformer des fichiers textes¶
Voyelles contre voyelles¶
Nous allons dorénavant travailler sur le fichier fichier_test_filtre.txt.
Permutation de voyelle
Le cerveau a des capacités étonnantes: il est capable de lire un texte dans lequel les voyelles ont été mélangées!! Tentons l'expérience.
Construire un fichier fichier_test_melange.txt où on a échangé les e avec les a et les o avec les u. Vous pouvez aussi coder un remplacement aléatoire d'une voyelle par une autre...
Cryptage¶
Principe
Le terme de cryptage désigne un ensemble de techniques, avec différents protocoles de codage, visant à rendre illisible un message, un texte ou autre contenu sensible.
Nous avons déjà rencontré le codage de César qui consiste à substituer une lettre par une autre en décalant d'une certaine valeur (la clé) les lettres de l'alphabet.
Codage de César avec choix de la clé
- Coder le fichier
fichier_test_filtre.txtpar le codage de César avec la clé de votre choix. - Imaginer un programme Python qui permet de tester l'ensemble des clés possibles pour décoder le texte crypté.
Nous allons améliorer ce codage en changeant la transformation utilisée.
Dans le codage de César avec un clé égale à 4, c'est la fonction \(f\) définie par \(f(x)=x+4\) qui permet le décalage des rangs de l'alphabet. Nous allons choisir maintenant une vraie fonction affine pour transformer: le décodage en sera alors plus difficile.
Codage affine
- Reprendre le travail de l'exercice précédent avec la fonction affine \(code\) définie pour tout \(x\) dans \([0,25]\) par \(code(x)=17x+5\).
- Construire le fichier
fichier_codage_affine.txtobtenu en cryptant le fichierfichier_test_filtre.txtpar le codage affine précédent. - Vérifier que la fonction affine \(decode\) définie par \(decode(x)=23x+15\) décode le fichier précédemment codé...
Decryptage¶
Comment analyser un texte, crypté ou non?
L'une des premières expériences réalisées est l'analyse fréquentielle des caractères constituant ce texte.
L'analyse fréquentielle
L'analyse fréquentielle consiste à déterminer la fréquence d'apparition des lettres (ou autre chose...) dans un texte.
Nous allons mettre en place l'analyse fréquentielle des deux textes fichier_test_filtre.txt et fichier_codage_affine.txt en utilisant les deux fonctions python suivantes:
def freq_lettre(texte, let):
"""
parameters:
-----------------
texte: string
let: caractere
returns
-----------------
float frequence de let dans texte
"""
cpt = 0
for carac in texte:
if carac == let:
cpt += 1
return cpt/len(texte)
def freq_lettre_texte(fichier_src):
"""
parameters:
-----------------
fichier_src: string
returns
-----------------
liste des frequences des minus dans texte
"""
minus = [chr(i) for i in range(97, 123)] #liste des minuscules
liste_freq = []
for elt in minus:
liste_freq.append(freq_lettre(fichier_src, elt))
return liste_freq
Analyse des fichiers texte
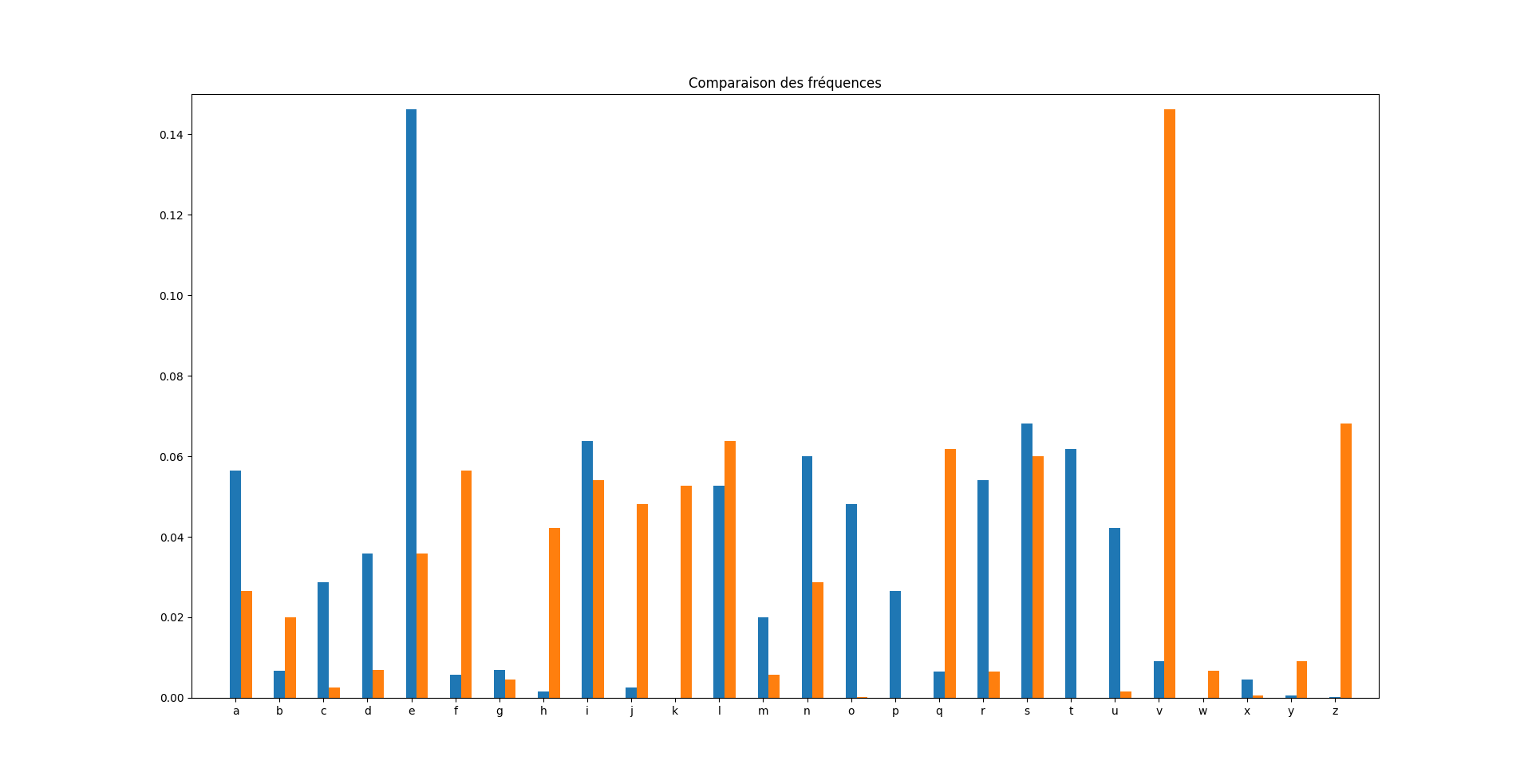
Utiliser les fonctions précédentes pour analyser les deux textes fichier_test_filtre.txt et fichier_codage_affine.txt.
Pour visualiser les résultats de l'étude précédente, nous allons utiliser un histogramme.
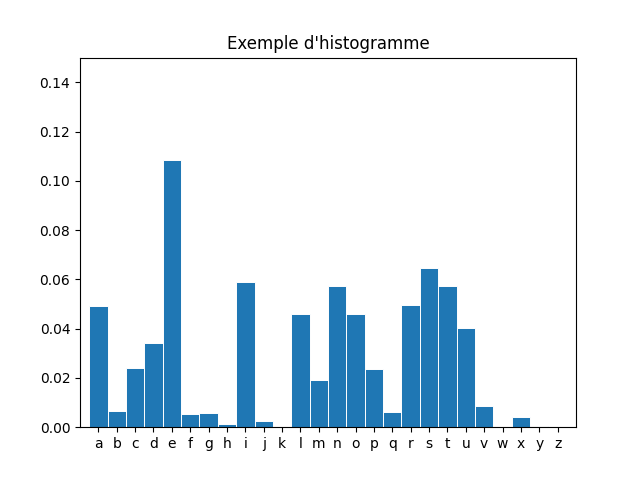
Pour construire un tel histogramme, il faut une liste en abscisse et une autre en ordonnée.
import matplotlib.pyplot as plt
import numpy as np
fichier_1 = 'fichier_test_filtre.txt' #fichier d'étude
fichier_etude_1 = open(fichier_1,'r')
f_1 = fichier_etude_1.read()
###################################################################################
fig, ax = plt.subplots()
minus = [chr(i) for i in range(97, 123)] #liste en abscisse
freq = freq_lettre_texte(f_1) #liste en ordonnee
ax.bar(minus, freq, width = 1)
plt.title(f"Analyse du fichier {fichier_1}")
ax.set(xlim = (-1, 26), xticks = np.arange(0, 26), ylim = (0, 0.15), yticks = np.arange(0,0.15,0.02))
plt.show()
###################################################################################
fichier_etude_1.close()
Faire des histogrammes
- Construire l'histogramme des fréquences du fichier
fichier_test_filtre.txt. - Construire un autre histogramme des fréquences du fichier
fichier_codage_affine.txt. - En analysant ces deux histogrammes, comment pouvons-nous retrouver les clés qui ont permis le codage affine?
Voici mes histogrammes(je les ai représenté sur le même graphique ce qui ne sera peut-être pas évident pour vous...):